Why LLMs.txt Doesn’t Work: The Definitive Verdict After Google’s May 2026 Guide

LLMs.txt is the most-promoted, least-effective piece of “AI SEO” the industry produced between mid-2024 and mid-2026. Google made the position official in its May 2026 AI Optimization Guide. The hard data behind that position has been in server logs for over a year. I’ve been writing about it since October 2025. None of this is news anymore.
This is the consolidated case: what LLMs.txt actually is, who pushed it, what server-log studies of 300,000 domains and 1,000 Adobe Experience Manager sites actually found, and what to build instead.
Key Takeaways
- Google’s May 2026 AI Optimization Guide explicitly names LLMs.txt as a tactic you do not need to implement, ending an 18-month vendor cycle that was promoting it as a ranking factor
- Two large-scale server-log studies (Flavio Longato across 1,000 Adobe Experience Manager domains, SE Ranking across 300,000 domains) both showed major AI crawlers do not request LLMs.txt files in any meaningful volume
- Anthropic, OpenAI, Meta, and Mistral have not endorsed or adopted the format either, so even outside Google there is no major LLM crawler reading these files
- You don’t have to delete an existing LLMs.txt file. Stop treating it as a ranking lever and stop billing time against creating one. Spend the budget on render mode, semantic HTML, citation tracking, and the SEO fundamentals Google’s guide actually endorsed
What LLMs.txt Was Supposed To Do
LLMs.txt is a proposal first surfaced in 2024 by Jeremy Howard at Answer.AI. The idea: a markdown file at the root of a domain that gives LLMs a structured summary of the site’s most important content, so AI crawlers could ingest the site more efficiently than parsing the full HTML. Think of it as a sitemap.xml-style hint file, but for AI training and inference rather than for traditional search crawlers.
It was a reasonable idea. The technical case wasn’t crazy. The problem was adoption. No major LLM company committed to reading it. The format had no enforcement mechanism, no governance body, no standardisation process. It existed as a proposal on a developer’s blog and a few prominent practitioner endorsements.
That didn’t stop the vendor cycle. Through 2025, dozens of SEO tools, agencies, and content shops began selling LLMs.txt as a ranking factor. “Generate yours in seconds.” “Future-proof your site for AI search.” “Tell Google’s AI which pages to prioritise.” None of it was supported by how the actual AI crawlers behaved.
What Google Actually Said in May 2026
The verdict is now in Google’s own documentation. The May 2026 AI Optimization Guide mythbusting section lists LLMs.txt files explicitly under “things you can ignore for Google Search”:
You don’t need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search. Note that Google may discover, crawl, and index many kinds of files in addition to HTML on a website: this doesn’t mean that the file is treated in a special way.
Google Search Central, AI Optimization Guide, May 2026
Gary Illyes from the Google Search Relations team had already said in earlier comments that Google “doesn’t support LLMs.txt and isn’t planning to,” but until May 2026 that wasn’t in an official documentation page. Now it is.
A standard caveat applies here, which I covered in my breakdown of the full May 2026 AI Optimization Guide. Google’s public documentation does not always match how their systems actually work. The 2024 ranking system leak made that gap public. But on LLMs.txt specifically, the practitioner evidence and the official position point the same direction, which is rare and worth taking seriously.
The Server-Log Evidence
This is the part the vendor blogs do not link to. Multiple independent studies have audited server-side logs for actual LLM bot traffic to LLMs.txt files. The pattern is consistent.

Flavio Longato: 1,000 Adobe Experience Manager domains, 30 days of CDN logs
Flavio Longato, an LLM Optimization strategist at Adobe, published a server-log audit across 1,000 enterprise sites running Adobe Experience Manager. He pulled 30 days of raw CDN logs and filtered for requests to /llms.txt. The results were unambiguous.
LLM-specific bots stayed away. No GPTBot, ClaudeBot, PerplexityBot, or similar were seen at all. Google still probes everything. Its desktop crawler accounted for 95% of all hits. SEO tools inflated the logs. Tools like Semrush Mobile and SiteAudit caused many hits, unrelated to LLMs.
Flavio Longato, LLMs Recommendation 2025 August
The same study found Bing made seven total requests across all 1,000 domains, all concentrated on a single site, and OpenAIBotSearch made ten calls. GPTBot itself was completely absent.
SE Ranking: 300,000 domains
SE Ranking’s March 2026 study scaled the question. They analysed 300,000 domains for LLMs.txt presence and AI citation behaviour. The headline finding: adoption is around 10% of large sites, but the file has no measurable impact on AI citation frequency. Their direct conclusion: “Our analysis of 300,000 domains shows that LLMs.txt doesn’t impact how AI systems see or cite your content today.”
Search Engine Land: tracked 10 sites
Search Engine Land tracked 10 sites that implemented LLMs.txt files and watched for AI traffic changes over the following weeks. Eight of the ten saw no measurable change. One site declined 19.7%. Two sites saw lifts of 12.5% and 25%, but the lifts traced back to unrelated factors (new editorial coverage, technical fixes, new backlinks). The LLMs.txt file itself never correlated with the visible changes.
I Was Saying This in October 2025
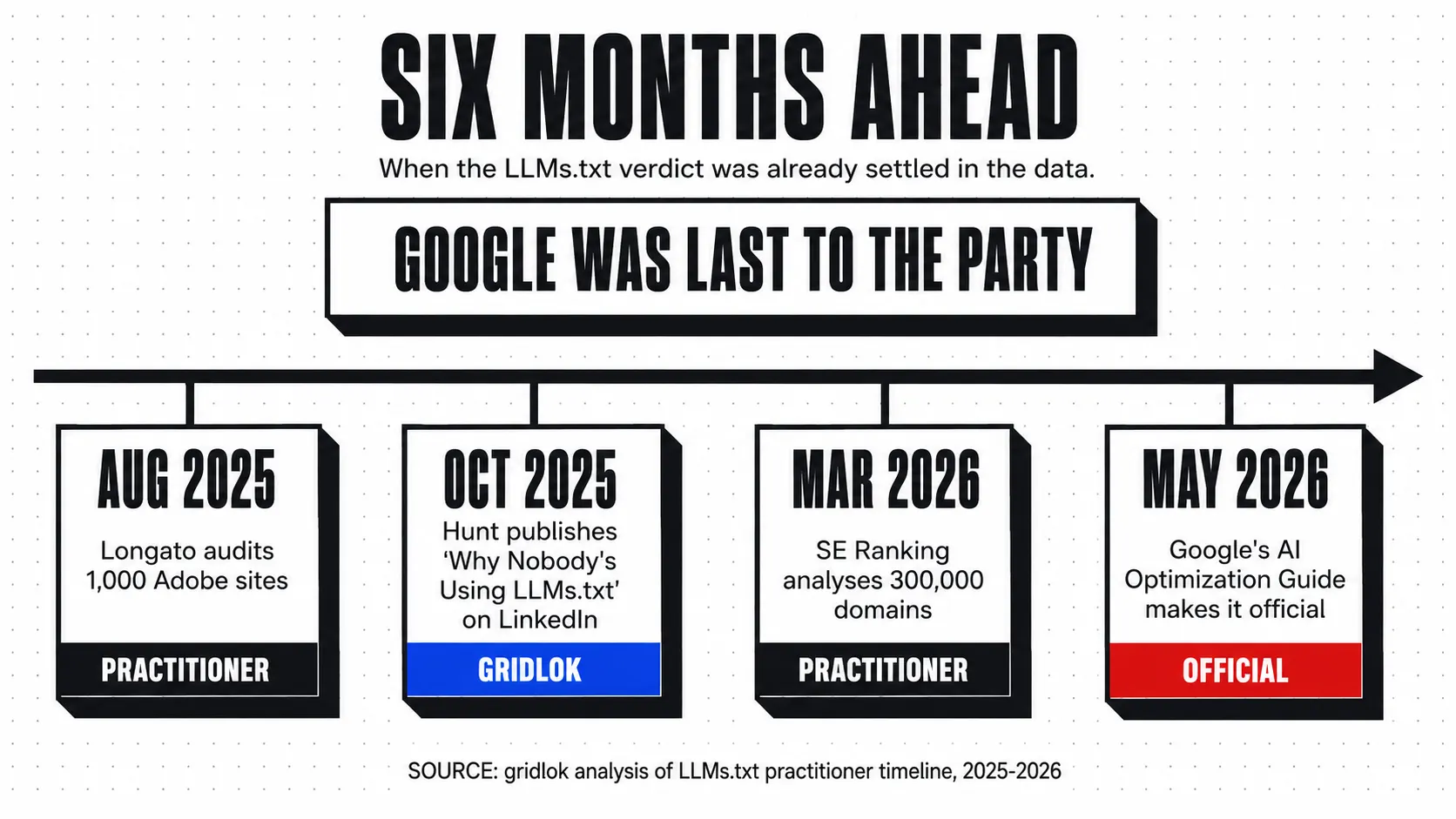
The data was visible to practitioners long before Google made it official. I covered the gap on LinkedIn in October 2025 in Why Nobody’s Using LLMs.txt. That piece walked through three points that all still hold seven months later.
First, server-log data showed zero meaningful requests from GPTBot, ClaudeBot, or PerplexityBot for LLMs.txt files. The bots that were checking robots.txt were not also checking LLMs.txt. Second, fewer than 1,000 websites worldwide had implemented the file at the time. Third, the most-prominent vendor pushing the implementation, Semrush, did not implement LLMs.txt on its own domain. The file returned 404. The vendor selling the implementation tool did not believe in the implementation enough to ship it themselves.
Reddit reactions to the format have followed the same arc. The most upvoted r/SEO thread on the topic put it directly:
There is not a single LLM that reads, supports, or uses llms.txt. Not ChatGPT. Not Claude. Not Gemini. Not Perplexity. None of them. This is a BS “standard” invented by people who got excited about slapping “AI” onto something and calling it innovation. If your “SEO expert” is spending billable hours implementing llms.txt instead of fixing your crawl errors, improving your site architecture, or building actual topical authority, fire them.
u/bareov, r/SEO, March 2026 (43 upvotes)
Why It Was Sold Anyway
The simplest explanation is the right one. LLMs.txt was easy to sell. A new file with “LLM” in the name, a 5-minute implementation, and a recurring billing item for “AEO setup” or “AI search readiness.” It was a perfect pitch shape for the AEO and GEO consultant cycle of 2025, which needed a clear deliverable that distinguished its work from traditional SEO.
The same dynamic produced the broader “AEO is the new SEO” narrative that another r/SEO commentator described in a thread that hit 204 upvotes:
Had 2 of my old clients leave recently because they wanted “GEO specialists” after hearing “GEO is the new SEO” from bigger agencies. Explained this exact point but they went with the hype. Sometimes the boring answer is the right answer.
u/aftabaliqu, r/SEO, July 2025 (204 upvotes)
LLMs.txt was the visible artefact of that hype cycle. Easy to point at, easy to bill against, easy to claim credit for. Whether it worked was a separate question that the vendor incentive structure was not built to answer.
What to Build Instead
The action list comes out of the same Google AI Optimization Guide that named LLMs.txt as ineffective, with practitioner additions Google chose not to address.
- Fix your render mode. If your site is built on Lovable, Bolt, v0, or any default React SPA, GPTBot and ClaudeBot see an empty HTML shell. That’s a real, measurable, high-severity SEO problem and LLMs.txt does nothing to fix it. Server-side rendering or static generation does. I covered the full diagnostic in Vibe Coding and SEO.
- Audit your robots.txt for the bots that actually matter. Robots.txt is read and respected by every major LLM crawler. If you want to allow GPTBot, ClaudeBot, PerplexityBot, Google-Extended, or block any of them, robots.txt is the place. LLMs.txt is not.
- Track which fan-out queries trigger your content. Google’s May 2026 guide officially named “query fan-out” as the mechanic that drives AI Overview and AI Mode citations. Knowing which specific fan-out queries ChatGPT generates for a topic is a research lever LLMs.txt was never going to give you. That’s the gap I built SubSeed to close. The Chrome extension surfaces the hidden fan-out queries and source citations from real ChatGPT sessions and turns them into actionable keyword research.
- Spend the implementation budget on author markup and entity consistency. Author schema, organisation schema, and consistent entity mentions across the web are practitioner-verified levers for citation that Google quietly omitted from the May 2026 guide. Their absence in the guide is not an endorsement of skipping them. I covered the absences in detail in my breakdown of the May 2026 guide.
FAQ
Sources & References
- Google Search Central (2026, May 15). “Optimizing your website for generative AI features on Google Search.” developers.google.com
- Hunt, J. (2025, October 29). “Why Nobody’s Using LLMs.txt.” LinkedIn. linkedin.com
- Longato, F. (2025, August). “LLMs Recommendation 2025 August: 30 days of CDN logs across 1,000 Adobe Experience Manager domains.” longato.ch
- SE Ranking (2026, March). “LLMs.txt: Why Brands Rely On It and Why It Doesn’t Work — 300,000 domains analysed.” seranking.com
- Search Engine Land (2026). “Does llms.txt matter? We tracked 10 sites to find out.” searchengineland.com
- Search Engine Roundtable (2026). “Google Search Team Does Not Endorse LLMs.txt Files.” seroundtable.com
- u/aftabaliqu (2025). “Google confirms normal SEO works for AI Overviews.” r/SEO. reddit.com
- u/bareov (2026). “How to spot an SEO noob: they’re telling you to implement llms.txt.” r/SEO. reddit.com
- Shepard, C. (2026, May 7). “AI Citation Ranking Factors.” Zyppy Signal. signal.zyppy.com
See what ChatGPT is really searching
SubSeed captures the hidden Google queries ChatGPT runs behind every answer and enriches them with search volume, CPC, and keyword difficulty.